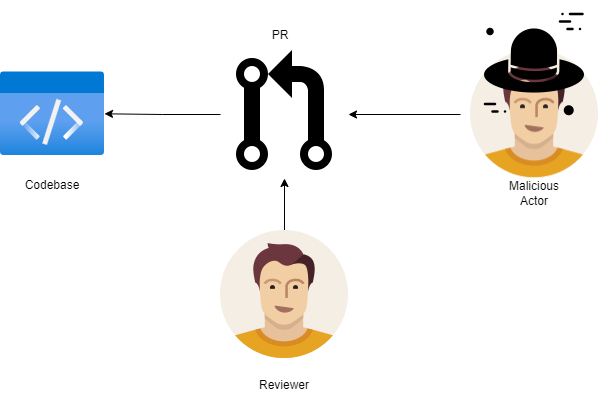
Over the last few years, some practices appear to be more a dogma than a value adding practice. One of this is Pull Requests.
Why PR's exist
- Malicious Code Prevention: Pull requests exist mostly as a practice accepted for
zero trust environments (ex. Open Source). An attack vector on this type of environment is the ability of anyone to contribute, meaning you could inject code that could create known vulnerabilities that packages will inherit. That is why maintainers validate code from unknown users.
- Highly Distributed Teams: PR's can be use for highly distributed teams (around the clock) as a way to do knowledge sharing. If someone in side A of the world can follow and understand the changes for a feature that is being developed in side B of the world.

The issue
IS there any value of doing PRs when people work collocated? What is the cost of PRs in trust environments?
The value that normally people give to PRs is the one of having a peer review process. Nevertheless, we will see later in this article that there are less invasive ways to do this.
Some costs of PRs are:
- Slow Delivery: PRs are a start and stop strategy where there is a gateway to merge code. This is time that needs to be taken by developers (writting & preparing a PR) and reviewers (reviewing, commenting, etc) to go through the process. At the same time is more time the code takes to get to production (merging, re-testing, etc). This is significant for features but also for fixes, meaning you can go from a response time of minutes to hours.
- Isolation work: When working on branches, devs work on code that works isolated but needs to be merged with a continuous stream of changes. This means that any test isolated will probably be invalidated upon merging.
- Lack of ownership: As work is done isolated, the developer who creates a PR delegates part or the responsibility to the reviewer. Humans don't have compilers or containers to run the code in our brain, meaning catching errors tends to be out of our realm.
- Egos: As catching errors tends to be out of our human realm, PRs tend to become a thing related to preferences (Style, patterns, etc). This hardly provides any value to the code as either tools like linters can do this automatically or it brings premature optimizations.
- Late feedback: Any valid recommendation is actually provided quite late in the process, when the code has already been written and validated. Causing rework that takes time.
The Alternatives
Pull requests are just one of the asynchronous peer code reviews styles. Is not the only way of doing peer reviews.
Some other types of peer reviews that I, personally, like are:
- Over-the-shoulder: The bases of this is to have a conversation over what has been or is being implemented. This creates a synchronous feedback loop on an async process. It does not fix all the shortcomings of a PR, but it creates a faster feedback loop.
- Pair Programming / Mob Programming: The idea is that multiple developers work in the same code base in the same computer, creating a synchronous feedback loop in a synchronous process. This with
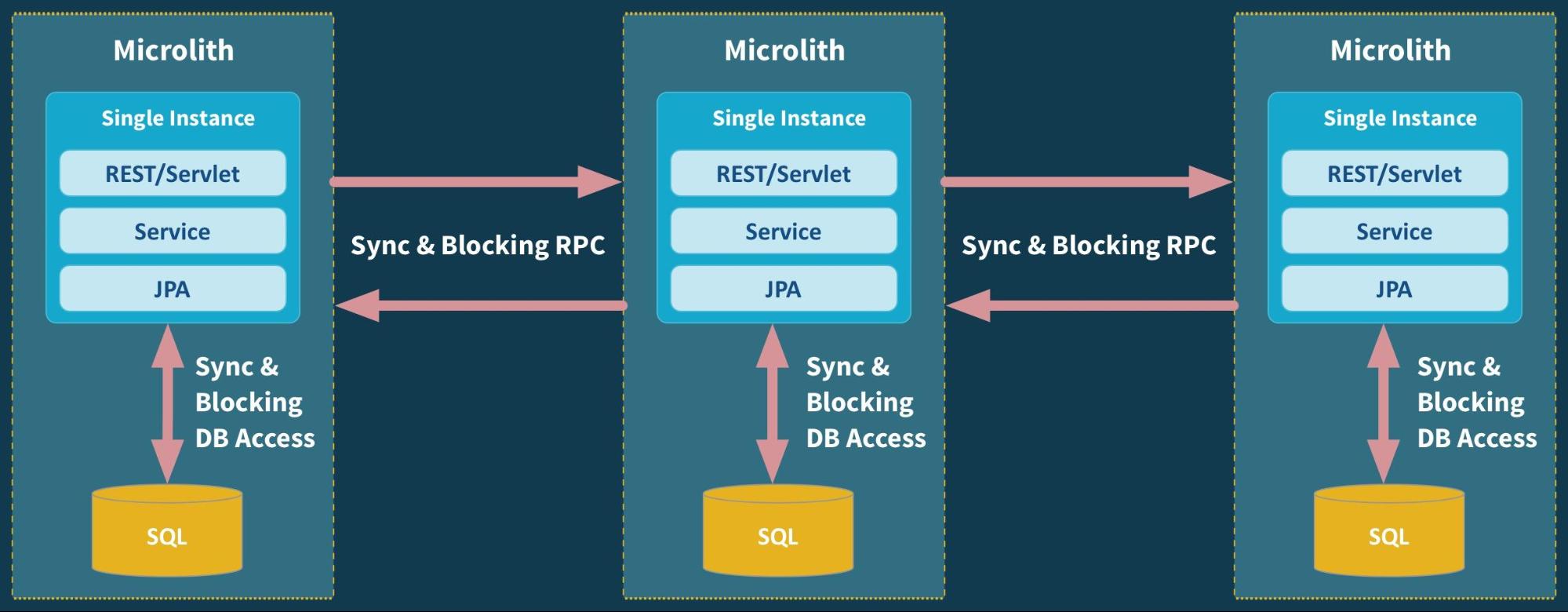
Trunk-based development allows very fast feedback loops at product level, and with the correct tools generates resilience and ownership among developers.
The disclaimer here is I have worked doing pair programming, TDD and trunk-based development for more than 5 years in multiple size companies, and it has always been a bliss.